On the Texags Politics thread on flat Earthers there was some disagreement about why a plane does not ascend away from the curvature of the Earth. I commented that to understand why a plane doesn’t ascend away from the Earth in straight and level flight we have to realize how big the Earth is. I clarified this comment by stating that for every mile of flight the Earth descends about eight inches, and that this descent is accounted for by the microcorrections made during flight. KeithDB suggested that “the plane flies at a max altitude and thus stays with a certain limit above the sphere, traveling in an arc around the sphere as it goes.” ’03ag stated that “through air speed or manipulating control surfaces you can generate an amount of lift equal to the force of gravity. Once those settings are found you will fly at a constant altitude. they don’t need to change unless atmospheric conditions change.” He further stated that since lift and gravity cancel each other out giving you a net zero radial force component, “your distance to the center of this radial force remains constant.” He seemed to disagree with me when I stated that the form of Newton’s second law had to be changed in order to account for curvilinear polar coordinates. Finally, JJxvi stated that “In a perfectly stable atmosphere, I believe the pilot could set his controls where lift=gravity and the plane would automatically fly in a orbit pattern just as something orbits the earth without needing course correction.”
Obviously there is considerable disagreement between myself and others on the politics board regarding why a plane does not naturally ascend. It is my goal in this post to show that the true explanation of why a plane does not naturally ascend is a bit more subtle than what is being suggested by others. Namely, I aim to show that setting lift force equal to the gravitational force does not produce a circular path. In fact, it produces a path in which the plane ascends if it is initially flying parallel to the ground. I then wish to look at a situation which may not yet have been mentioned (it has been explicitly mentioned since I began writing this post): the case that the lift force is just less than the gravitational force so that the combination of those two forces gives us a force consistent with a true net centripetal force. I argue that this explanation is implausible. Finally I look at the case where the plane must correct its flight path. I show why the size of the Earth matters, and how it obscures the necessary corrections.
We begin with some math that will be necessary to explore this phenomenon in greater detail. First of all, we will only consider direct flights between two points on the globe. This simplifies the mathematics so that everything can be examined in two dimensions. The relevant information we need is the plane’s height above the ground and how far it is into its trip. For the purpose of this post I will use two different representations for this information. I will use the typical Cartesian coordinates and I will use polar coordinates, with the center of the Earth as the origin in both instances. In Cartesian coordinates we can write the position vector as

The height of the plane can be extracted from here as follows:

where  is the radius of the Earth. On the other hand, we can write the position vector in polar coordinates as
is the radius of the Earth. On the other hand, we can write the position vector in polar coordinates as

here r is the radial distance of the plane from the center of the Earth. Height is then simply  We need a second coordinate in polar coordinates. That will be the angular displacement. So in polar coordinates we have r for the height and
We need a second coordinate in polar coordinates. That will be the angular displacement. So in polar coordinates we have r for the height and  for the angular displacement. We can relate the Cartesian and polar representations as follows:
for the angular displacement. We can relate the Cartesian and polar representations as follows:





We now come to the physics. The only relevant physics we need to know is Newton’s second law:  and what forces are relevant. In its vector format Newton’s second law is equally valid in Cartesian and polar coordinates. If we look at Newton’s second law in a particular Cartesian component, its form will not change:
and what forces are relevant. In its vector format Newton’s second law is equally valid in Cartesian and polar coordinates. If we look at Newton’s second law in a particular Cartesian component, its form will not change:



However, the form of Newton’s second law changes for a polar component since the coordinate system itself varies with time. In that case we have
![\dot{\vec{R}}=\frac{d}{dt} \left[ r \hat{r} \right] =\dot{r} \hat{r} + r \dot{\hat{r}},](https://s0.wp.com/latex.php?latex=%5Cdot%7B%5Cvec%7BR%7D%7D%3D%5Cfrac%7Bd%7D%7Bdt%7D+%5Cleft%5B+r+%5Chat%7Br%7D+%5Cright%5D+%3D%5Cdot%7Br%7D+%5Chat%7Br%7D+%2B+r+%5Cdot%7B%5Chat%7Br%7D%7D%2C&bg=f5f6f7&fg=444444&s=0&c=20201002)


The second derivative can be found simply by taking the derivative of the above expression, where to get the time derivatives of the polar unit vectors we go back to their definition and use the chain rule. The second derivative is

Therefore, Newton’s second law in polar components is

Obviously the form of Newton’s second law is not preserved in polar components, because if it was the above equation would be

One final thing to note about the polar formalism was that it was derived very generally. We did not assume anything to be moving in a circle. However, we can see where the introductory physics centripetal acceleration formula comes from in the above equation. Obviously, for the radius to remain unchanged it is necessary that the radial component of the force is directed inward with a magnitude

The final piece of physical information we want to consider before examining particular scenarios is what forces we will be looking at. At any instant in time let’s break all the forces into components that are perpendicular or parallel to the ground. To make this problem a little simpler, we will assume that the plane is going at a constant speed parallel to the ground. This means we only have to worry about physics in the dimension perpendicular to the ground. In that dimension, we will have gravity, which will be denoted by  , and lift, which will be denoted by
, and lift, which will be denoted by  Gravity is simple. Newton told us that gravity is
Gravity is simple. Newton told us that gravity is

where  is the mass of the Earth and m is the mass of the plane, as before, and the minus sign denotes that gravity pulls towards the Earth rather than pushes away. The physics of lift, on the other hand, is far more complicated. You have to worry about atmospheric conditions, the geometry of the wing, the attack vector etc. Luckily for us, we won’t have to worry about any of that as the lift will be completely determined by the situation that we are analyzing, as we will soon see.
is the mass of the Earth and m is the mass of the plane, as before, and the minus sign denotes that gravity pulls towards the Earth rather than pushes away. The physics of lift, on the other hand, is far more complicated. You have to worry about atmospheric conditions, the geometry of the wing, the attack vector etc. Luckily for us, we won’t have to worry about any of that as the lift will be completely determined by the situation that we are analyzing, as we will soon see.
Now that we have the math and underlying physics down, let’s look at our relevant examples. First, let’s examine what happens when  or in other words when lift perfectly balances out the force of gravity. In this case, the net force on our plane is zero. So what happens to a plane if it’s flying parallel to the ground? We can position the plane so that in Cartesian coordinates it is initially at (0, y), and therefore will have a height of
or in other words when lift perfectly balances out the force of gravity. In this case, the net force on our plane is zero. So what happens to a plane if it’s flying parallel to the ground? We can position the plane so that in Cartesian coordinates it is initially at (0, y), and therefore will have a height of  . After flying for an infinitesimal amount of time it will be at (dx, y) in that same cartesian coordinate system, and its new height,
. After flying for an infinitesimal amount of time it will be at (dx, y) in that same cartesian coordinate system, and its new height,  will be
will be
 ,
,

As we can see, the plane does indeed ascend when it is flying parallel to the ground and the lift force is equal and opposite of gravity. The reason I’ve done the above analysis for an infinitesimal translation is to account for the possibility that for a physical translation gravity and/or lift may change by an appreciable amount even in our hypothetical situation where the atmosphere is spherically symmetric. However, if we plug in realistic numbers such as dx=10 km and initial height at 8km then:

or in other words, after flying ten kilometers the plane should have ascended seven meters. An ascent of seven meters will not change gravity or lift appreciably. We can, for all intents and purposes, say that over that flight of 10 kilometers the gravity and lift remain constant, and thus constantly cancel. So while my initial calculation was for an infinitesimal translation, we can see that this effect is real over 10 km when we plug in actual numbers, and weird things like varying gravity or varying lift can’t overcome this effective ascent in this case. So here, the ascent is real.
Before moving on, let’s examine this case in one other way. Recall that the radial component of Newton’s second law is

Since we’re examining the case where gravity is equal and opposite of lift, we have  and
and

Since, for the plane to fly,  it is clear that the radius is increasing from the polar formalism as well. We can positively conclude from this discussion that if a plane is flying parallel to the ground and the lift force is equal and opposite of gravity, the plane will spontaneously “rise” in the sense that it will fly away from the curvature of the Earth. Obviously this ascent is limited in range as ultimately lift will decrease as the atmosphere thins out, but for a distance like 10km this is a real effect when flying parallel to the ground with your forces in equilibrium. At this point it should be amply demonstrated that in the case where we “have equivalent lift acting parallel and in the opposite direction” to gravity, the idea of a plane ascending is not “flatly wrong on paper and in practice,” as was suggested on the forums.
it is clear that the radius is increasing from the polar formalism as well. We can positively conclude from this discussion that if a plane is flying parallel to the ground and the lift force is equal and opposite of gravity, the plane will spontaneously “rise” in the sense that it will fly away from the curvature of the Earth. Obviously this ascent is limited in range as ultimately lift will decrease as the atmosphere thins out, but for a distance like 10km this is a real effect when flying parallel to the ground with your forces in equilibrium. At this point it should be amply demonstrated that in the case where we “have equivalent lift acting parallel and in the opposite direction” to gravity, the idea of a plane ascending is not “flatly wrong on paper and in practice,” as was suggested on the forums.
The next thing to examine is what happens when we have the “Goldilocks lift,” or when the lift is just right so that it counteracts gravity exactly to produce a net centripetal force:

It is true that were this condition met then you would have a plane that travels in a circular path around the globe. But this probably isn’t exactly what’s going on either. To see why, we’ll have to look at the actual numbers.
On the forums it was suggested that by moving out of the idealized world of physics I’m moving the goalposts. This is not the case. The situation we were discussing when using the idealized physics model was the first one. The claim was made by several posters that in the idealized case that lift equals gravity the plane would fly in a circle around the globe. I have shown that’s not true. It’s an entirely different claim that if the Goldilocks lift were hit and maintained that the plane would fly in a circle around the globe in the idealized model. That claim is true in the idealized model. The Goldilocks lift is probably not maintainable throughout a flight in reality, though.
Essentially, on average, you’re probably right. Once the plane hits its cruising altitude its average lift probably is the Goldilocks lift. But I don’t think the airplane maintains its course by carefully measuring and regulating the lift force. The difference between the gravitational force and the lift force to hit the Goldilocks lift is about 0.1% of the total lift force. I know when I flew Cessna 172s there was absolutely no way I could regulate the lift that precisely. I doubt even state-of-the-art airplanes could regulate it to that precision. Even in the physically idealized perfectly spherically symmetric atmosphere, regulating your lift that precisely over the course of an entire flight would probably not be possible. As such, course corrections would have to be made to keep the plane at a stable altitude.
The reason that this argument might be seductive is that it is predicated on the assumption that planes fly parallel to the ground. This is how it looks to anyone who has piloted an aircraft or taken a flight on an aircraft. However, if you make that assumption, you end up with the first situation. Checkmate round-Earthers! But not so fast. If you aim the plane towards the horizon it flies very close to the Goldilocks lift. However, the difference in angle between aiming for the horizon and flying parallel to the ground is practically imperceptible. This is due to the enormity of the Earth relative to how high we fly above it (I can work the math out on this if anyone wants to see it). When the biggest reference point we see while flying is the ground and it appears to us that we are flying parallel to it, it’s natural to assume that that is indeed the case, and we are quickly lead to the first situation: we are flying parallel to the ground with lift being equal and opposite of gravity. The second factor in not noticing this effect must be the fact that the lift is not perfectly controllable, and as such the pilot or the autopilot is always making minor corrections to its course. Seeing that the Earth curves away from a plane flying parallel to the ground so slowly, again due to the enormity of the Earth, this effect must get lost in the noise of those corrections as the pilot or autopilot will indeed correct to fly at the correct.
So I hope I have convinced you of a few things. One, that in the case that the lift is equal to the gravitational force and the plane is flying parallel to the ground the plane will indeed ascend spontaneously. Two, since lift cannot be maintained at an absolute constant it is not correct to assume that setting the plane to the perfect level of lift is the ultimate answer to why planes fly in a circle around the globe. Corrections would still need to be made. Three, I hope I’ve shown why this argument is seductive, as it appeals to intuition about how planes fly and then it appeals to the first situation, where gravity and lift are equal and opposite. And finally, I hope I have shown that the seductive, intuitive argument is fallacious, and you can realize the fallacy by realizing just how enormous the Earth is.
Please direct all discussion regarding this post to the relevant Texags threads.


![ds^2= -dt^2 + a^2(t) \left[ \frac{dr^2}{1 - kr^2} + r^2 d \Omega^2 \right]](https://s0.wp.com/latex.php?latex=ds%5E2%3D+-dt%5E2+%2B+a%5E2%28t%29+%5Cleft%5B+%5Cfrac%7Bdr%5E2%7D%7B1+-+kr%5E2%7D+%2B+r%5E2+d+%5COmega%5E2+%5Cright%5D&bg=f5f6f7&fg=444444&s=0&c=20201002)





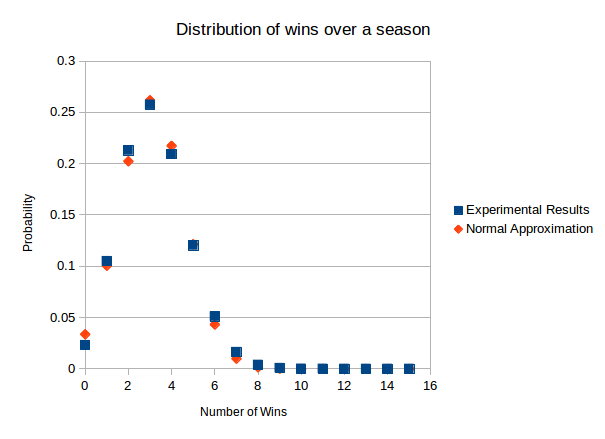
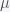 is the expected value and $\latex \sigma$ is the standard deviation. Since we’re looking for the distribution of a sum of random variables we can find the expected value and variance quite simply based on the individual random variables that are summed. Since the individual random variables can only be 1 or 0, if
is the expected value and $\latex \sigma$ is the standard deviation. Since we’re looking for the distribution of a sum of random variables we can find the expected value and variance quite simply based on the individual random variables that are summed. Since the individual random variables can only be 1 or 0, if  is the probability of winning the ith game then
is the probability of winning the ith game then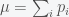
 .
.![P[x=n]=\int_{n-0.5}^{n+0.5} f(x)dx](https://s0.wp.com/latex.php?latex=P%5Bx%3Dn%5D%3D%5Cint_%7Bn-0.5%7D%5E%7Bn%2B0.5%7D+f%28x%29dx&bg=f5f6f7&fg=444444&s=0&c=20201002)

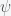 , called the wavefunction which is what we are solving for, and V, called the potential which is already known. Everything else can be thought of as constants. The potential contains all the information regarding the surroundings of the object that we’re studying, while the wavefunction contains all of the information regarding the object we’re studying itself. The usual process is we take the Schrodinger equation, plug in all the information that we have about our surroundings in V, and solve for the wavefunction. The way we extract useful physical information from the wavefunction is a little odd at first glance, but it doesn’t take long to get used to. Nevertheless, extracting physical information from the wavefunction is beyond the scope of this post. Here, we only aim to find it and discuss its dimensionality.
, called the wavefunction which is what we are solving for, and V, called the potential which is already known. Everything else can be thought of as constants. The potential contains all the information regarding the surroundings of the object that we’re studying, while the wavefunction contains all of the information regarding the object we’re studying itself. The usual process is we take the Schrodinger equation, plug in all the information that we have about our surroundings in V, and solve for the wavefunction. The way we extract useful physical information from the wavefunction is a little odd at first glance, but it doesn’t take long to get used to. Nevertheless, extracting physical information from the wavefunction is beyond the scope of this post. Here, we only aim to find it and discuss its dimensionality. Without going through the gory details, this gives us
Without going through the gory details, this gives us

 where
where  is called the angular frequency and E is called the energy. The solution to the above for a particular value of E is called a stationary state and is given by
is called the angular frequency and E is called the energy. The solution to the above for a particular value of E is called a stationary state and is given by
![\psi(\textbf{r},t) = Ae^{i \left[\textbf{k} \cdot \textbf{r} - \omega(k) t \right]},](https://s0.wp.com/latex.php?latex=%5Cpsi%28%5Ctextbf%7Br%7D%2Ct%29+%3D+Ae%5E%7Bi+%5Cleft%5B%5Ctextbf%7Bk%7D+%5Ccdot+%5Ctextbf%7Br%7D+-+%5Comega%28k%29+t+%5Cright%5D%7D%2C+&bg=f5f6f7&fg=444444&s=1&c=20201002)
![\psi(\textbf{t},t) = \frac{1}{(2 \pi)^{3/2}} \int g(\textbf{k}) e^{i \left[\textbf{k} \cdot \textbf{r} - \omega(k) t \right]} d^3k](https://s0.wp.com/latex.php?latex=%5Cpsi%28%5Ctextbf%7Bt%7D%2Ct%29+%3D+%5Cfrac%7B1%7D%7B%282+%5Cpi%29%5E%7B3%2F2%7D%7D+%5Cint+g%28%5Ctextbf%7Bk%7D%29+e%5E%7Bi+%5Cleft%5B%5Ctextbf%7Bk%7D+%5Ccdot+%5Ctextbf%7Br%7D+-+%5Comega%28k%29+t+%5Cright%5D%7D+d%5E3k+&bg=f5f6f7&fg=444444&s=1&c=20201002)
 .
. represents a vector. Remember that vectors and operators are geometric objects that are independent of the basis you used to represent them. For example, you could chose a Euclidean vector represented by (1,0) in one basis, but (0,1) in another basis. Similarly, an operator that picked out how far to the right the vector extended with respect to the first basis would have its matrix representation changed in the second basis. This doesn’t actually change any intrinsic properties of the vector or the operator, it just changes their representation. We do a similar thing in quantum mechanics. The Schrodinger equation and further analysis I gave above were with respect to a particular basis, called the position basis. We could choose to do the problem in another basis, such as the momentum basis, if we so desired. However all of the intrinsic stuff, like the physical information contained in a state and the more abstract stuff regarding state spaces, is true in all bases. Thus quantum mechanics is naturally stated in a more abstract language that makes the study of the state space desirable, and natural. It is where the underlying structure of quantum mechanics lies.
represents a vector. Remember that vectors and operators are geometric objects that are independent of the basis you used to represent them. For example, you could chose a Euclidean vector represented by (1,0) in one basis, but (0,1) in another basis. Similarly, an operator that picked out how far to the right the vector extended with respect to the first basis would have its matrix representation changed in the second basis. This doesn’t actually change any intrinsic properties of the vector or the operator, it just changes their representation. We do a similar thing in quantum mechanics. The Schrodinger equation and further analysis I gave above were with respect to a particular basis, called the position basis. We could choose to do the problem in another basis, such as the momentum basis, if we so desired. However all of the intrinsic stuff, like the physical information contained in a state and the more abstract stuff regarding state spaces, is true in all bases. Thus quantum mechanics is naturally stated in a more abstract language that makes the study of the state space desirable, and natural. It is where the underlying structure of quantum mechanics lies.